要介紹 Attention 機制,就不能錯過這篇經典:Google 在 NIPS2017 上發表的論文《Attention Is All You Need》。本篇將透過這篇論文來理解 Attention 機制的原理與應用。
Attention 機制要解決什麼樣的問題?
在序列化建模,如語言建模( language modeling)或機器翻譯 (machine translation)上,RNN、LSTM 和 GRU 是被確立為此領域中的最先進技術。不過由於序列化的運算限制仍然一直存在,因此提出一個基於 attention 機制的 Transformer 的神經網絡,允許訓練時可平行化處理的部分、提高訓練效率,且論文提到在8個 P100 GPU 上訓練了12個小時後即達到 state-of-the-art 的結果。
模型架構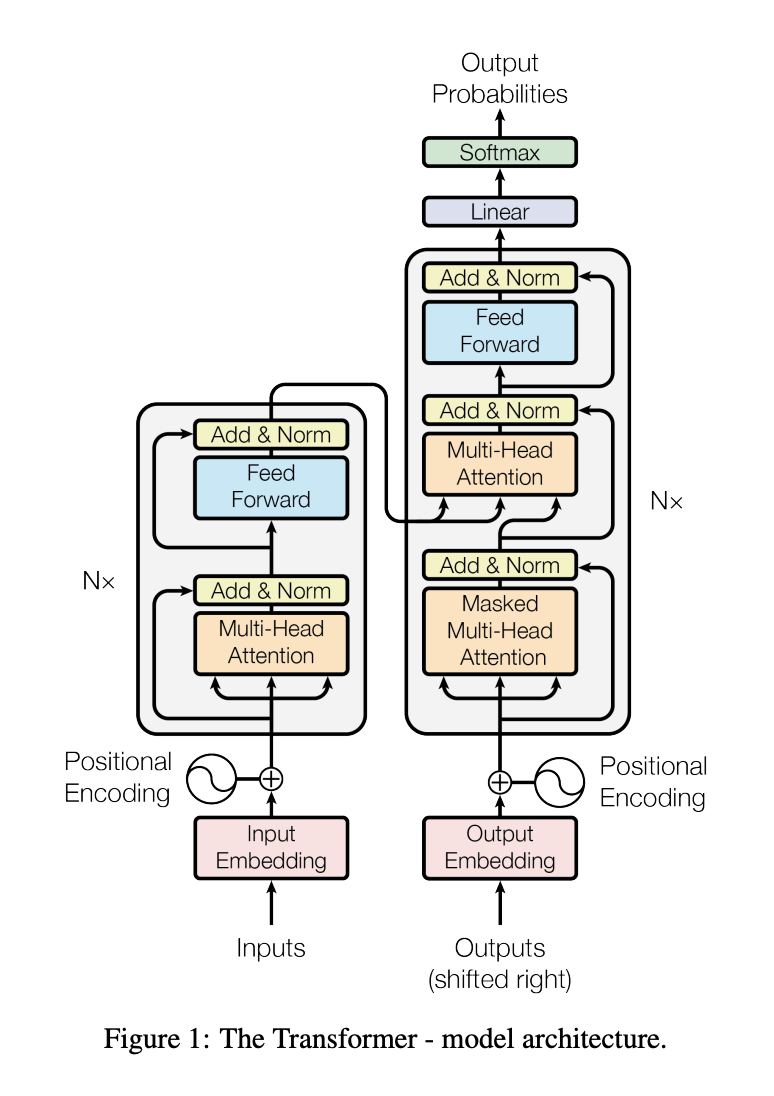
Transformer 建立於 encoder-decoder 的架構之上:
encoder (左半邊):
由 N = 6 的相同 layer 所組成,每一層有 2 個子層(sublayer)分別是:
multi-head self-attention mechanism(自我注意力機制)position-wise fully connected network(全連接層)decoder (右半邊):
同樣是由 N = 6 的相同 layer 所組成,每一層有 3 個子層:
muti-head attention:將 encoder 層的輸出(output)作為輸入(input)。masked multi-head self-attention:用遮罩(mask)的機制,讓位置 i 的字詞只能 attend 到自己以前的字詞(小於位置 i ),不能向後偷看(大於位置 i )。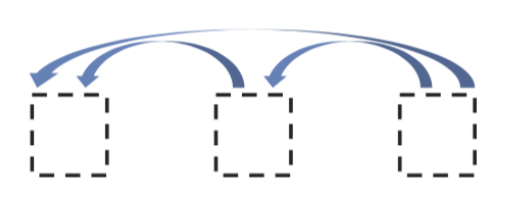
fully connected feed forward
encoder 和 decoder 皆以殘差連接(Residual Connection)的方式此加深網路,並透過 Layer Normalization 加速收斂。
總結
Transformer 的動機在於解決 RNNs 以下問題:
attention機制來解決長距離依賴的問題,相距越遠的字詞會越難找到彼此的資訊論文表示在翻譯任務上,Transformer 在訓練上比 RNN 或 CNN 更快,在 English-to-German 和 English-to-French 的翻譯達到新的技術水平,並提到後續希望擴展到文本以外的處理,例如音頻、圖像或是影片。
在 [魔法陣系列] Recurrent Neural Network(RNN)之術式解析 文末提到要介紹 attention 機制,終於交差囉,感到開心~

